日前(6月20日 - 25日),数据库顶级会议2021 ACM SIGMOD在西安举行,深圳计算科学研究院科研团队及其合作者发表的4篇论文被大会收录。作为数据库领域公认最具影响力的国际性学术会议,SIGMOD与ICDE、VLDB并称为国际数据库三大顶级会议,其收录论文代表了数据库相关技术的最高水平,也是未来技术发展的重要风向标。这4篇论文分别在选择性估算、图的无损压缩方案、增量图算法、交互式搜索Top-k数据等数据库相关研究领域实现了创新突破,彰显了深算院在大数据领域强大的核心人才储备、科研文化底蕴和技术创新能力。
一、Consistent and Flexible Selectivity Estimation for High-Dimensional Data
作者:Yaoshu Wang , Chuan Xiao , Jianbin Qin , Rui Mao, Makoto Onizuka, Wei Wang, Rui Zhang, Yoshiharu Ishikawa
关键词:selectivity estimation;high-dimensional data;piecewise linear function;deep neural network
摘要:选择性估算的目的是在数据库中估计满足给定选择标准的数据数量,这对于密度估计、异常检测、查询优化和数据整合等许多应用都至关重要并富有挑战性。本文提出了一种新的基于深度学习的模型,可以灵活地拟合任意距离函数和查询对象的选择性曲线,同时保证模型的输出在阈值增加的时候不会减少。为了提高大规模数据下估算的准确性,本文提出了将数据划分为多个不相交的子集并在每个子集上建立一个局部模型的简洁高效策略。经真实数据集实验,本文提出的模型在准确度上始终优于最新的模型,且具有很好的实用性。
论文链接:https://dl.acm.org/doi/10.1145/3448016.3452772
二、Making Graphs Compact by Lossless Contraction
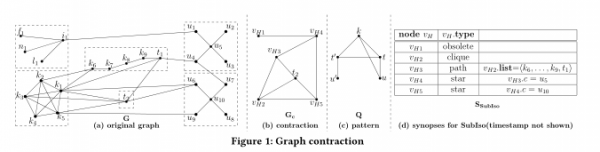
作者:Wenfei Fan, Yuanhao Li, Muyang Liu, Can Lu
关键词:graph data management;graph contraction;graph algorithms
摘要:本文中提出了一种将大图化为小图,并能够作为多个应用程序同时在同一个图上运行的通用且无损的优化压缩方案。该方案将过期数据、星、团和路径压缩为超点,超点为每个查询类Q携带一个概要SQ,此概要抽象了被压缩部分的核心特征,并以此来回答Q中的查询。该方案还能够优先处理图中最新的数据。此外,我们可以移植现有的查询算法,在可能的情况下通过使用概要来计算精确的答案(精确解),并且仅在必要的情况下解压缩超点。实验结果表明,该方案能将图大小平均减少了71.2%,使查询的计算效率分别提高了1.53倍、1.42倍和2.14倍。
论文链接:https://doi.org/10.1145/3448016.3452797
三、Incrementalizing Graph Algorithms
作者:Wenfei Fan,Chao Tian,Ruiqi Xu,Qiang Yin,Wenyuan Yu,Jingren Zhou
关键词:incrementalization;boundedness;fixpoint algorithm
摘要:增量算法对动态图分析起到重要作用,但其编写和分析较困难。已有增量图算法较少,其中能够提供性能保证的算法更少。本文朝着增量图算法迈进了一步,提出了对现有批处理算法进行增量化的方法,确定了一类不动点算法是可增量化的。展示了如何从算法A 推导相对有界的增量算法A∆。本文提供了保证正确的和相对有界的一般条件,推导出的算法∆通过采用与A相同的逻辑和数据结构,最多使用时间戳作为附加的辅助结构就能够满足该条件。在此基础上,证明了各种图中心的算法可以增量化并确保相对有界地。通过实验验证了该增量算法的可扩展性和有效性,推导出A∆与专门设计的增量算法相比在效率和空间上表现更好。
论文链接:https://doi.org/10.1145/3448016.3452796
四、Interactive Search for One of the Top-k

作者:Weicheng Wang,Raymond Chi-Wing Wong,Min Xie
关键词:top-k query;user interaction;data analytics
摘要:传统的top-k查询根据用户的偏好查找最佳的k个数据(即top-k数据)。但用户很难明确地指定他/她的偏好,且用户也不希望逐个读取所有数据来找到最满意的数据。本文研究了通过用户交互增强top-k查询,并实现减少用户所耗费的精力。为此,在二维空间中,本文提出了2D-PI算法,该算法对问题的数量是渐近最优的;在高维空间中,提出了两种算法RH和HD-PI,分别在算法执行时间和提问的问题数上都有很好的效果。大量的实验表明,本文的算法可以比现有的算法在更短时间内提出更少问题,并返回用户满意的结果。
论文链接:https://doi.org/10.1145/3448016.3457322
数读研究院科研成果:
截至2021年7月8日,研究院共发表/录用高水平论文54篇,其中CCF A类44篇;申请专利/PCT共23项,授权发明专利2项。科研成果比肩全球任何一支大数据学术团队。
